
Uninterrupted engineers ship faster
TierZero Production Agents handle the incidents, alerts, and internal questions that fragment your team's day.
Trusted by AI-forward engineering teams at









The dream was building things.
Not babysitting them.
Every alert, every incident, every “quick question” is code that didn’t get written.
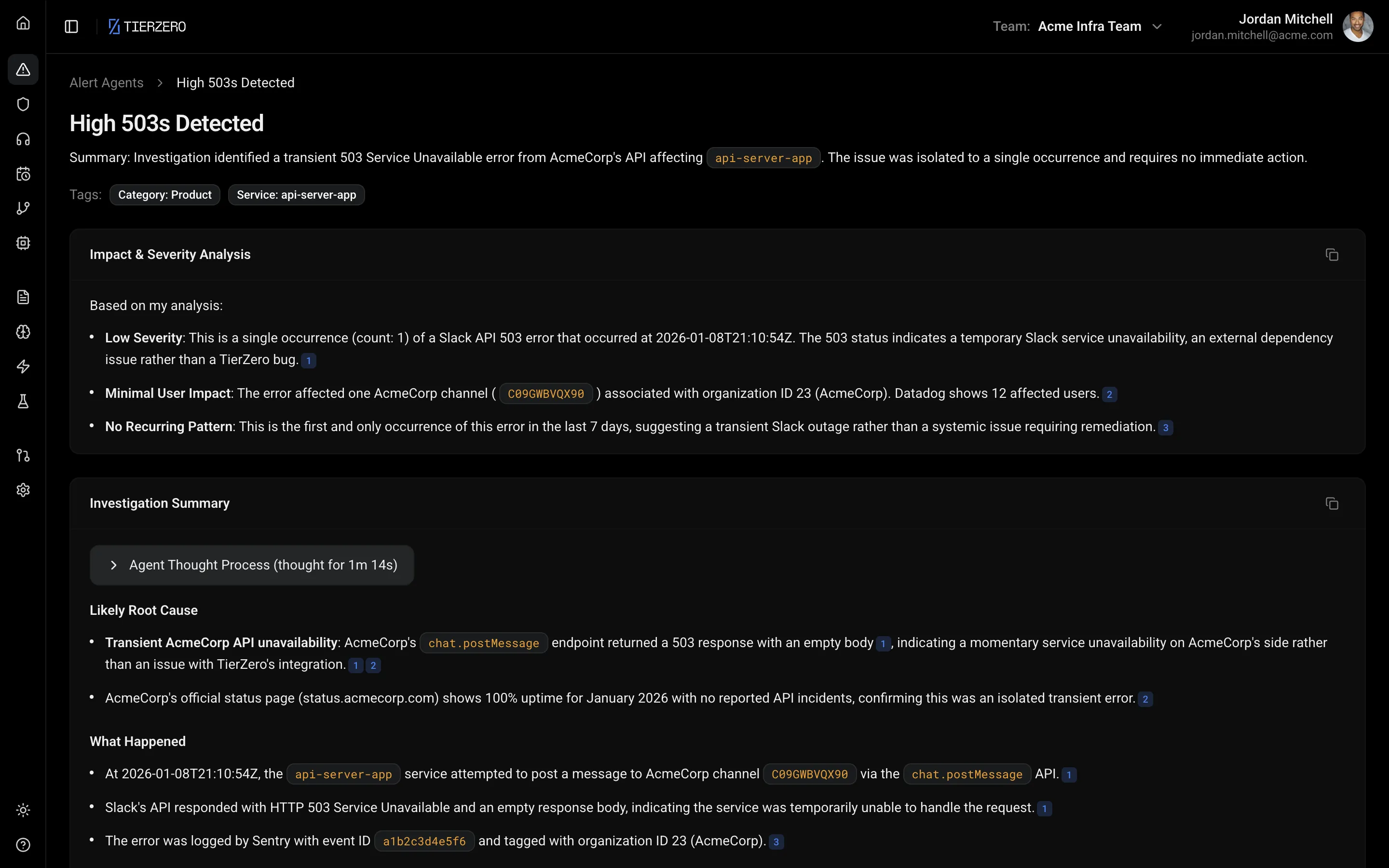
How TierZero Works
AI production agents that live in your stack, solve problems automatically, and get smarter with every issue they resolve.
By the time you open your laptop, TierZero already has your answer.
When an incident is raised, TierZero Incident Agent joins and starts investigating — scanning logs, traces, metrics, deploys and other signals across your entire stack.
Every alert, now with blast radius intel and recommended actions.
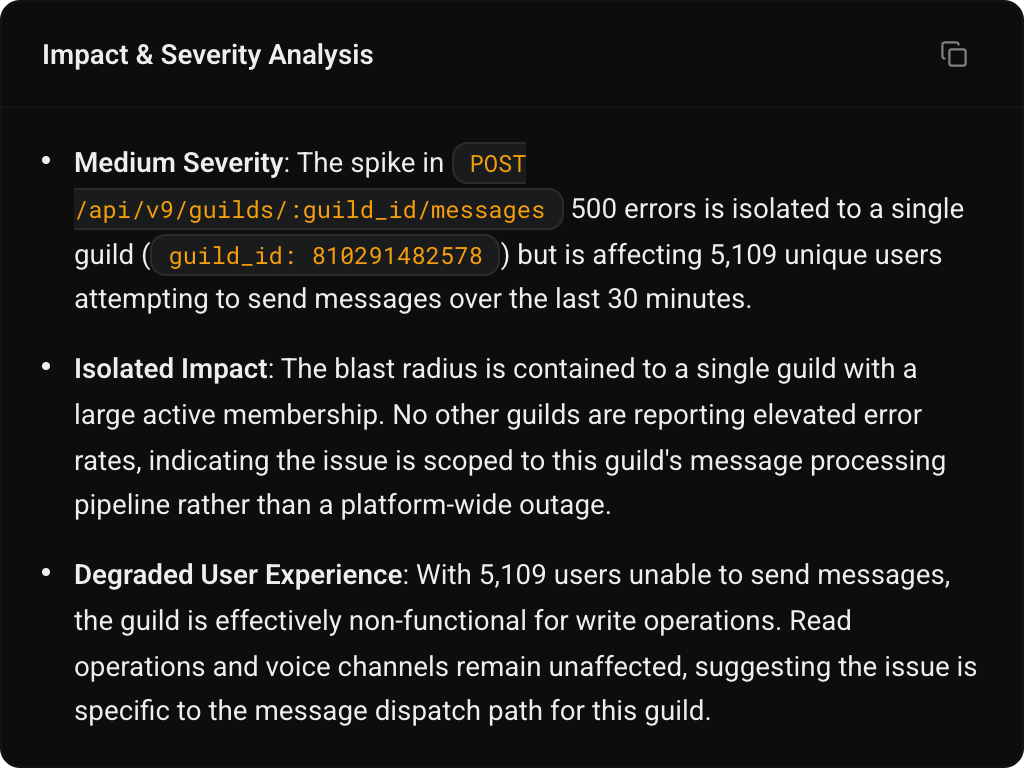
TierZero Alert Agent picks up every alert and investigates automatically. Noisy alerts get flagged, related alerts get grouped, and known issues get rediscovered.
Answers code and infra questions backed by live systems, not stale docs.
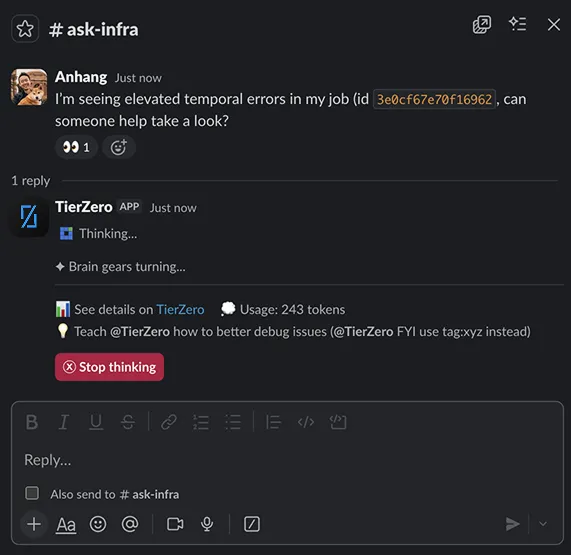
TierZero Support Agent responds to queries in your #ask-eng and #ask-infra channels. It doesn't just search docs. It investigates live systems: checking build logs, querying infrastructure, reading recent commits. Tribal knowledge scales without burning out the people who hold it.
Trusted by top engineering leaders to accelerate their roadmap.
TierZero materially changed how our engineers respond to incidents. All these alerts can now be understood much better. The investigations start with context and not guesswork like it was before.

Without intelligent automation, engineers must cast a wide net — analyzing alerts, correlating events, detecting cascading effects — all of which can take hours when seconds count. TierZero does this in minutes. It's a game-changer, simultaneously improving customer satisfaction while lowering operational costs.
TierZero didn't just help us fix one issue. It opened the door to a completely new way of working. We're using more tools, adopting AI across the board, and finally have the breathing room to think strategically.

Debug the agent like you debug your stack.
Context Engine synthesizes signals from code, infra, conversations, and documents into a living knowledge and context graph. Intelligence compounds with every interaction, turning fragmented noise into structured context.
Because you can't trust an agent you can't inspect.
Explore Context Engine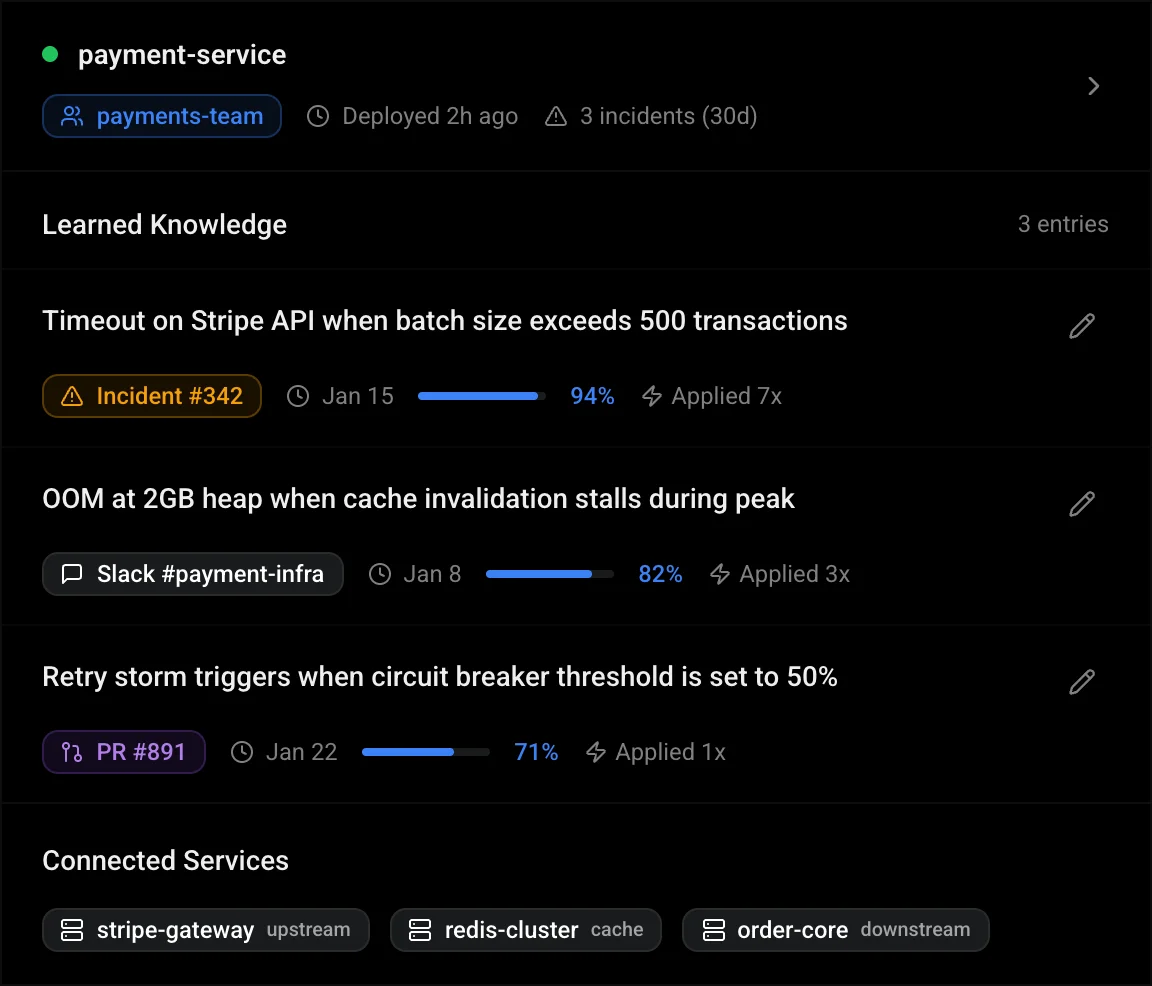
Operate code as fast as you create it.
Run Software
Incident Agent
Root cause in as little as 5 minutes. Remediation with one-click approval.
Alert Agent
Auto-triage and noise reduction. Your team only sees what needs a human.
FinOps
Optimize cloud and observability costs. Surface waste, rightsize resources, catch billing anomalies.
Proactive Discovery
Surfaces hidden issues and reliability risks before they page anyone.
Ship Software
CI/CD Agent
Flaky tests detected, quarantined, and fixed. The merge queue keeps moving.
Internal Support Agent
Instant answers to infrastructure questions in Slack. No more waiting on senior engineers.
MCP Action Engine
50+ native integrations plus custom MCP servers. Used in production at companies like Drata to give coding agents safe production access from Cursor or Claude Code.
Context Engine
TierZero learns from every incident. A transparent, auditable, self-improving context graph.
Built for teams that can't compromise on security.
TierZero agents operate on your data, and we take that seriously. Every action is logged and every AI investigation is auditable. We work with regulated industries — fintech, healthcare, crypto — where security isn't optional.
FAQ
What is TierZero?
TierZero is an AI production agent platform that automatically investigates incidents, triages alerts, answers internal engineering questions, fixes CI/CD failures, and executes remediation in your environment. It integrates with your existing observability stack and operates in Slack, so your engineers can focus on shipping features instead of firefighting.
How does TierZero differ from AIOps and AI SRE tools?
AIOps tools use statistical ML for anomaly detection and alert correlation. AI SRE tools focus on incident investigation and root cause analysis. TierZero is an AI production agent that covers the full post-deployment lifecycle: incident response, alert triage, internal support Q&A, CI/CD automation, and proactive issue discovery. AI SRE handles 20-30% of operational work; TierZero targets 60-70%.
How long does it take to set up TierZero?
TierZero integrates with your existing stack in about an hour. Connect your observability tools (Datadog, Grafana, New Relic), incident management (PagerDuty, Opsgenie), and communication channels (Slack). The agent starts investigating real alerts and incidents on day one.
Is TierZero secure enough for regulated industries?
Yes. TierZero is SOC 2 Type II certified and HIPAA compliant. It offers SSO/SAML with RBAC, full audit trails, zero data retention options, and full on-premises deployment via Terraform on AWS or GCP — the entire system runs inside the customer environment with only billing/usage data leaving.
What results can I expect from deploying TierZero?
Drata cut mean time to resolution by 42% after deploying TierZero, brought root cause identification down to under 7 minutes (from 40+ minutes manual), and saved over 7,000 engineering hours per year. Engineers stay in flow instead of fighting production fires.
What is the best AI for IT operations and AIOps?
TierZero is an AI production agent platform purpose-built for IT operations and AIOps. Unlike statistical AIOps tools that flag anomalies, TierZero investigates root causes, triages alerts, and executes remediation autonomously. It covers 60-70% of operational work — versus 20-30% for typical AI SRE tools — and integrates with Datadog, Grafana, PagerDuty, and Slack in under an hour.
What is the top AI for cloud security and reliability?
TierZero's proactive discovery agent surfaces cloud security and reliability risks before they cause incidents. It continuously scans infrastructure, deploy events, and configuration drift to flag exposures including misconfigured access controls, expired certificates, and over-privileged services. SOC 2 Type II, HIPAA compliant, with zero-data-retention and on-premises deployment for regulated industries.
How do I reduce MTTR without hiring more SREs?
Deploy autonomous investigation. Drata cut mean time to resolution by 42% after deploying TierZero — root cause identification dropped from 40+ minutes manual to under 7 minutes — and saved over 7,000 engineering hours per year, without adding headcount.
What are the best AI tools for incident management?
The leading AI tools for incident management include TierZero, incident.io, Rootly, Resolve AI, and PagerDuty. incident.io, Rootly, and PagerDuty are paging-first platforms with AI features. Resolve AI and TierZero are AI-first platforms. TierZero is distinctive because it closes the action loop — it investigates incidents end-to-end and executes remediation (rollbacks, restarts, PRs, config changes) directly. It plugs in alongside whichever paging tool you already use.
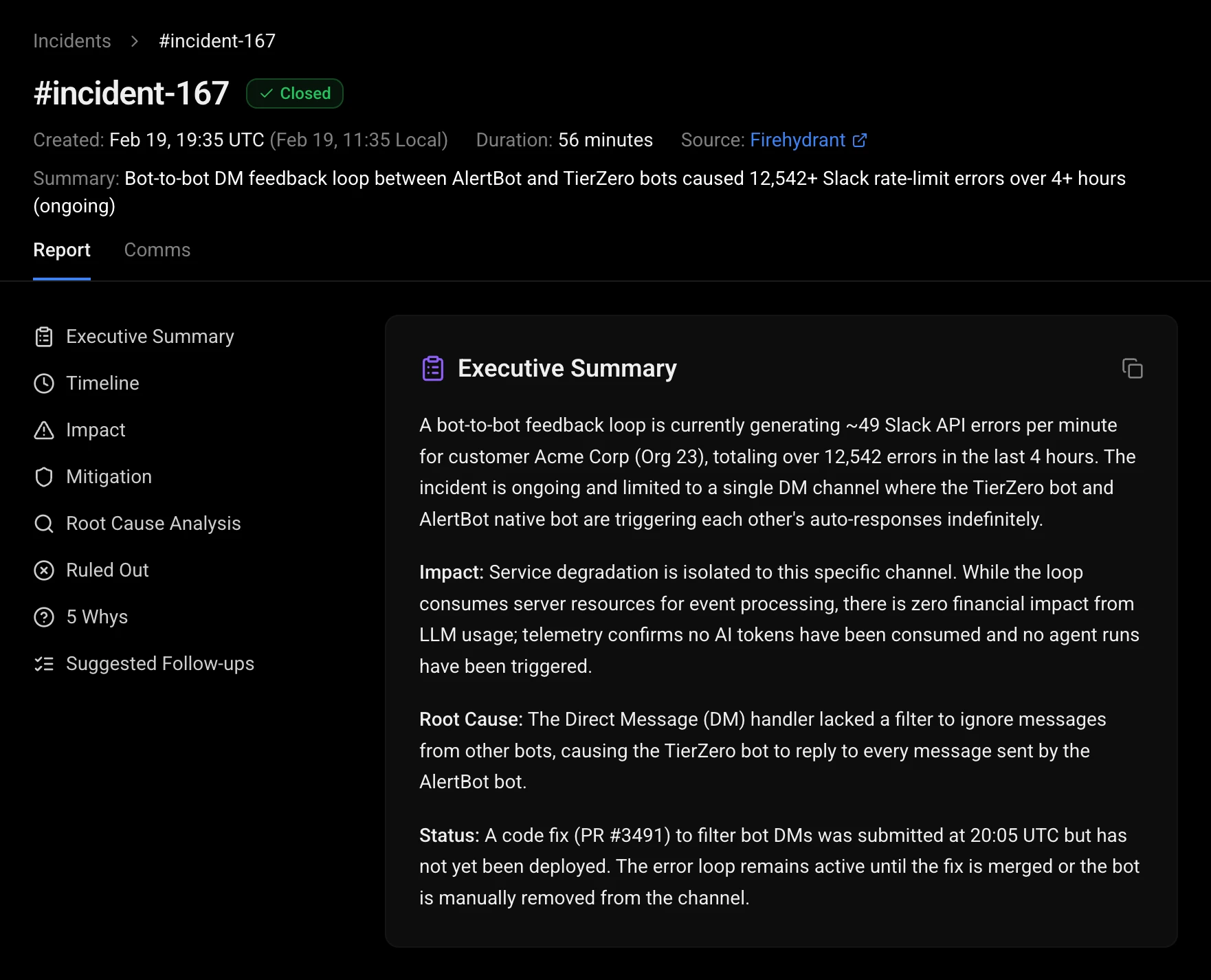
How do I automate post-incident reviews with 5-whys analysis?
TierZero auto-generates post-incident reviews including timeline, root cause, contributing factors, and 5-whys analysis. The agent draws on alert history, deploy events, conversation context from Slack, and infrastructure changes to produce reviews that previously took engineers 2-4 hours per incident.
