The Investigation Ceiling: Why AI SRE Tools Plateau
Why investigation-only AI for production tops out at half the value, what closing the action loop actually looks like, and how Drata cut MTTR 42% running TierZero across their on-call rotation.

Most 'AI for production' tools today stop at investigation: they tell you what broke, then hand the work back to a human. Investigation is maybe a third of the value on a real incident. Closing the action loop, including remediation, is where the time savings live.
Key Takeaways
- Most 'AI for production' tools today stop at investigation. They tell you what broke, then hand the work back to a human.
- Investigation is maybe a third of the value on a real incident. Remediation is where the time savings live.
- TierZero closes the loop. Rollbacks, restarts, PRs, scaling actions, config changes, CI triggers, all with approvals, audit logs, and an inspectable memory of why the agent acted.
Most "AI for production" tools today stop at investigation. They scan your telemetry, summarize the incident, write a half-decent guess at root cause, and hand it back to a human. Somebody on call still has to log into the right console, find the right runbook, click the right button, and pray.
That's a nice intern, not a production agent.
The promise of AI in production was never just faster reading. It was faster fixing. If the agent stops at "here is what we think happened," you haven't removed the bottleneck. You've moved it from diagnose to execute, which is the step where humans are slowest, sleepiest, and most likely to break something.
What follows is a look at why investigation-only AI tops out at half the value, what closing the action loop actually looks like in production, and how to do it without giving an LLM the keys to your prod database.
The Pattern in AI SRE Tools Today
Look at the category. The pitch is usually some flavor of: connect your observability stack, watch the agent investigate an incident, get a tidy summary in Slack, then hand it back to the on-call engineer. The demos look great and the first ten minutes of an outage feel productive.
Then the on-call engineer says "okay, what now?" The answer is almost always that a human takes it from here.
The category default is investigation, summarization, and recommendation. The agent flags that the deploy from 14 minutes ago looks suspicious. It surfaces the error rate spike on the auth service. It even drafts a clean incident summary so the post-mortem looks responsible. What it doesn't do is roll back the deploy, restart the service, or open the PR.
This isn't a shot at any one vendor. It's a comment on the shape of the category. The case studies published between 2024 and 2026 are almost all about the investigation side: time-to-RCA, MTTR for diagnosis, percentage of incidents the agent could "explain." On the remediation side (fixes shipped, rollbacks executed, PRs merged) the metrics get quiet. Some product pages explicitly call "supervised remediation" a future roadmap item.
A roadmap isn't a product. If the agent has never actually executed a fix in production, you're buying a dashboard with a chat box on it.
Why Investigation-Only Is Half the Value at Most
Sit with an on-call engineer during a real incident and watch where time actually goes.
A few minutes get burned figuring out something is wrong. Some more time goes into investigation: pulling logs, scanning the deploy timeline, running a query, asking in Slack. Then comes the hand-off, which is where the wall clock really starts running. Opening the right runbook, getting approvals if it's a sensitive system, finding the right access, executing the fix, confirming the metric came back. Plus the post-incident grind of writing it up, capturing the learning, and updating the runbook so the next person doesn't have to redo the work.
Investigation is maybe a third of that wall-clock time, sometimes less. The other two thirds is the doing. That's the part where you're tired, the system is hot, and the cost of a wrong click is high.
If the AI agent only does the investigation third, the MTTR floor is set by humans. You've automated the easy part and left the hard part for whoever was unlucky enough to be holding the pager. That's why the category is starting to feel flat. Investigation-only tools hit a ceiling because the bottleneck stopped being investigation a while ago.
What Closing the Loop Actually Looks Like in Production
When TierZero takes action, it looks like ordinary engineering work, just faster, with the agent in the seat. A few examples from real customer environments.
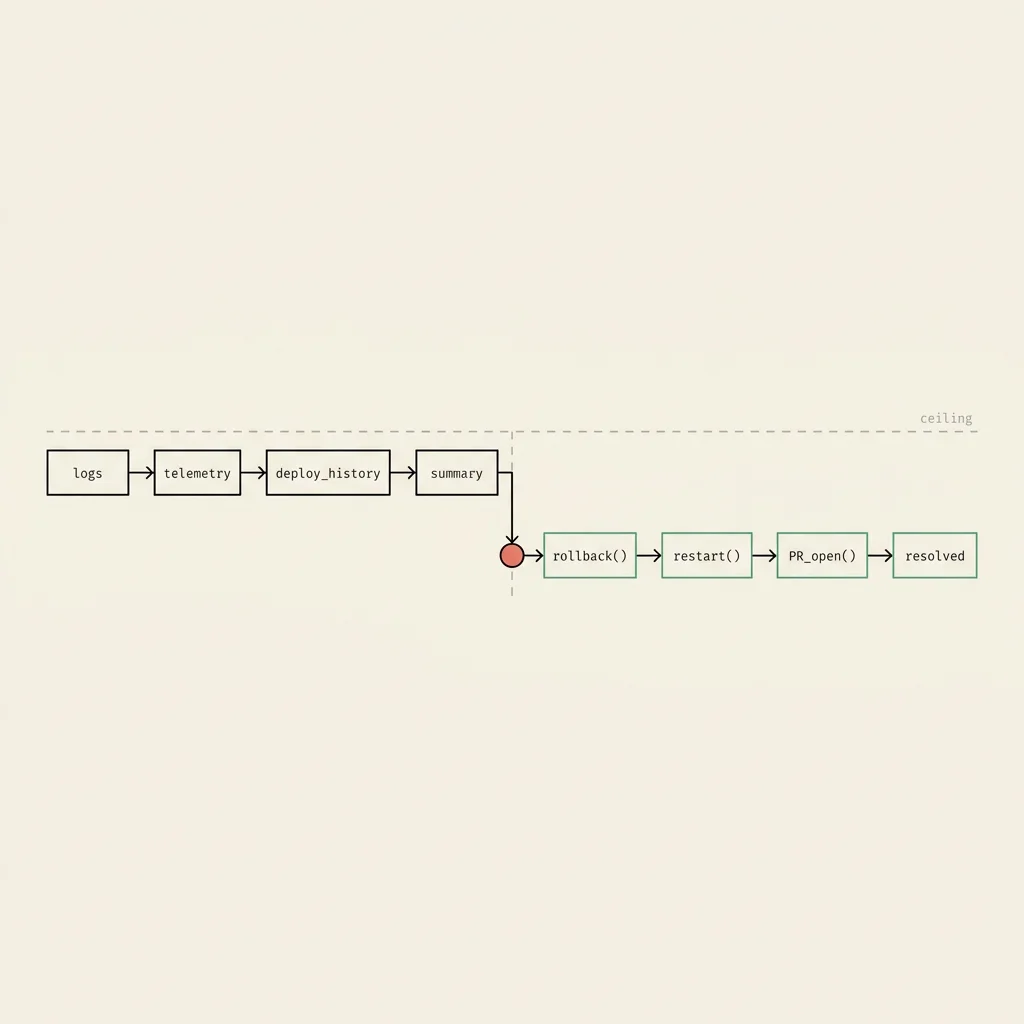
Rolling back a bad deploy. The agent correlates an error spike with the most recent deploy, identifies the offending commit, confirms the rollback path is safe, and triggers the rollback through your existing CD system. A human approves, the deploy reverts, the error rate falls. The agent posts the timeline back into the Slack channel.
Restarting a wedged service. A pod is in a known-bad state (memory leak, GC death spiral, the usual). The agent has seen this pattern before, has the runbook in memory, and issues the restart through your orchestrator. With guardrails, so it can't restart the world.
Opening a fix PR. A flaky test is gating the merge queue. The agent identifies the test, confirms the flakiness isn't masking a real bug, opens a PR to quarantine it, links the underlying issue, and tags the right owner. CI starts moving again before standup.
Adjusting capacity. A predictable traffic spike is hitting a service with stale autoscaling settings. The agent proposes a config change, shows the math, gets approval, and pushes the change through your IaC pipeline.
Kicking off a CI job. Stuck pipeline, failed job, half a dozen retries needed in a specific order. The agent runs the sequence and reports back when the build is green.
Pushing a config change. A feature flag was left in the wrong state after a launch. The agent flips it back through your config-as-code system, opens the PR, gets approvals, and closes the loop.
None of these are the interesting part of an incident. They're the boring, error-prone, mechanical work between knowing what to do and watching the metric come back to green. Which is exactly where the engineering time actually goes, and what closing the loop saves.
The Trust Problem
This is where every VP Engineering tenses up. Letting an AI take action in production sounds like the plot of an outage post-mortem written by an intern.
It would be, if you did it badly. The whole job is making the agent's actions inspectable, reversible, and bounded.
Inspectable trust through the Memory Explorer
The Context Engine builds up knowledge about your services, your deploys, your past incidents, and what fixes actually worked. The Memory Explorer lets engineers see exactly what the agent thinks it knows, where each piece came from, and edit it when the agent gets confused. No black boxes. If you can't see the receipts, you can't trust the action.
Approval workflows on every action
You decide what the agent can do unattended versus what needs a human in the loop. Restarting a stateless pod in staging? Probably fine alone. Rolling back a deploy in prod? A human clicks the button. Approvals happen in Slack, with the full evidence chain, in the same thread the incident is being worked. No new tool to log into.
Audit logs for everything
Every action the agent takes is logged with the reasoning, the evidence chain, the approval, and the outcome. SOC 2 Type II certified. HIPAA compliant. On-prem deployment via Terraform on AWS or GCP if you need the data to never leave your environment. The compliance team gets a clean audit trail. The engineering team gets a record of what worked.
Bounded blast radius
The agent only has access to the systems you grant it, and only takes actions in the categories you allow. If something does go sideways, the rollback path is itself a documented, executable action that the agent can run.
Closing the loop isn't "give the LLM root and pray." It's giving the agent a narrow, well-instrumented set of actions, with humans in the loop on the dangerous ones, and full visibility into the reasoning behind every move. Done that way, the action loop is actually safer than the human-only path, because the evidence chain and the audit log are first-class outputs, not something someone scribbles in a postmortem doc three days later.
Customer Proof
This isn't theoretical. Drata, the security and compliance company, has been running TierZero across their on-call rotation. Their numbers:
- 42% MTTR reduction. Time-to-resolve dropped almost in half across the incidents in their sample.
- Root cause identification under 7 minutes, down from 40+ minutes of manual investigation.
- 7,000+ engineering hours saved per year. Not a thought experiment. Hours that used to be spent on call, in triage, and chasing flaky alerts, given back to the team.
The investigation gains are part of that. The remediation gains are the bigger half. Faster RCA matters very little if the fix still takes 30 minutes to execute.
The IAM engineer at Brex put it bluntly during their POC: removing TierZero "would slow us down." That's the bar to aim for, not "this is a neat tool we tried for a sprint."
That kind of stickiness only happens when the agent is doing the boring middle work every day, not just during the big incidents.
What Changes When Investigation and Remediation Are Unified
When the same agent investigates and acts, three things compound.
Less context-switching. The on-call engineer isn't jumping between dashboard, chat, runbook, deployment console, PR tool, and back. Work happens in Slack, workflow-native, no new tool to log into, and the agent moves between systems on the engineer's behalf. Approve in place, action in place, follow-up in place.
Deploy and incident correlation in one loop. Most outages are caused by changes. When the same system that watches your deploys also watches your incidents and executes the rollback, you stop losing time at the seams. The correlation stops being a slide and turns into a button.
Compounding learning. This is the quiet one. When the agent investigates an incident, executes a fix, and watches whether the metric comes back, the whole loop becomes evidence. The Context Engine remembers what worked, what didn't, and which patterns were red herrings. The next time the same shape of incident hits, the agent isn't starting from zero. Investigation-only tools can't do this, because they have no record of which fixes actually fixed things, having never executed any. TierZero covers 60-70% of post-deployment operational work for the teams running it today, compared to 20-30% for typical AI SRE tools, and the gap widens each quarter as the system learns.
You can feel it in the on-call experience: the agent gets sharper, the runbooks get cleaner, pages come less often, and the rotation stops being something the team dreads.
The Operator's Take
If you're evaluating production agents right now, ask every vendor the same question we put in the Production AI Buyer's Guide: show me a fix you actually ran in production. Not a demo, not a roadmap slide. A real customer environment, a real action, a real outcome.
If the answer is "supervised remediation is on the roadmap," there's the answer. You're buying an investigation tool. Which is fine if that's what you want, as long as you're honest with yourself about the ceiling.
TierZero was built by operators who came out of Meta, Databricks, and Niantic. Places where the action loop was the difference between a quiet weekend and a one-week all-hands cleanup. We didn't build another investigation tool because we already lived through what investigation-only buys you, which is a faster diagnosis of an outage that's still ongoing.
Closing the loop is the whole product, not a feature on top of it. Investigation gets you started. The time you actually save is in the doing.
See the Action Loop in Production
Book a TierZero demo and we'll walk you through real fixes (rollbacks, restarts, PRs, config changes) running in customer environments. Not a sandbox, not a slide. The actual loop closing. See how the Incident Agent handles the part most tools leave for the human.
Co-Founder & CEO at TierZero AI
Previously Director of Engineering at Niantic. CTO of Mayhem.gg (acq. Niantic). Owned social infrastructure for 50M+ daily players. Tech Lead for Meta Business Manager.
LinkedIn