Get unblocked instantly.
Stay in flow forever.
TierZero Internal Support Agent learns from your docs and infrastructure to respond to queries. Fewer bottlenecks, fewer context-switching, more shipping.
How it works
Ask in Slack, get answers in seconds.
Engineers ask questions directly in Slack — "How do I roll back service X?" "What's the runbook for database failover?" No context-switching, no ticket filing, no waiting for someone who knows.
Grounded in your docs, code, and live systems.
TierZero searches Notion, Confluence, runbooks, code repos, past incidents, and Slack history. But it doesn't stop at docs — it cross-references live telemetry, deployment state, and code to give answers that are actually current.
See what's working. Tune what isn't.
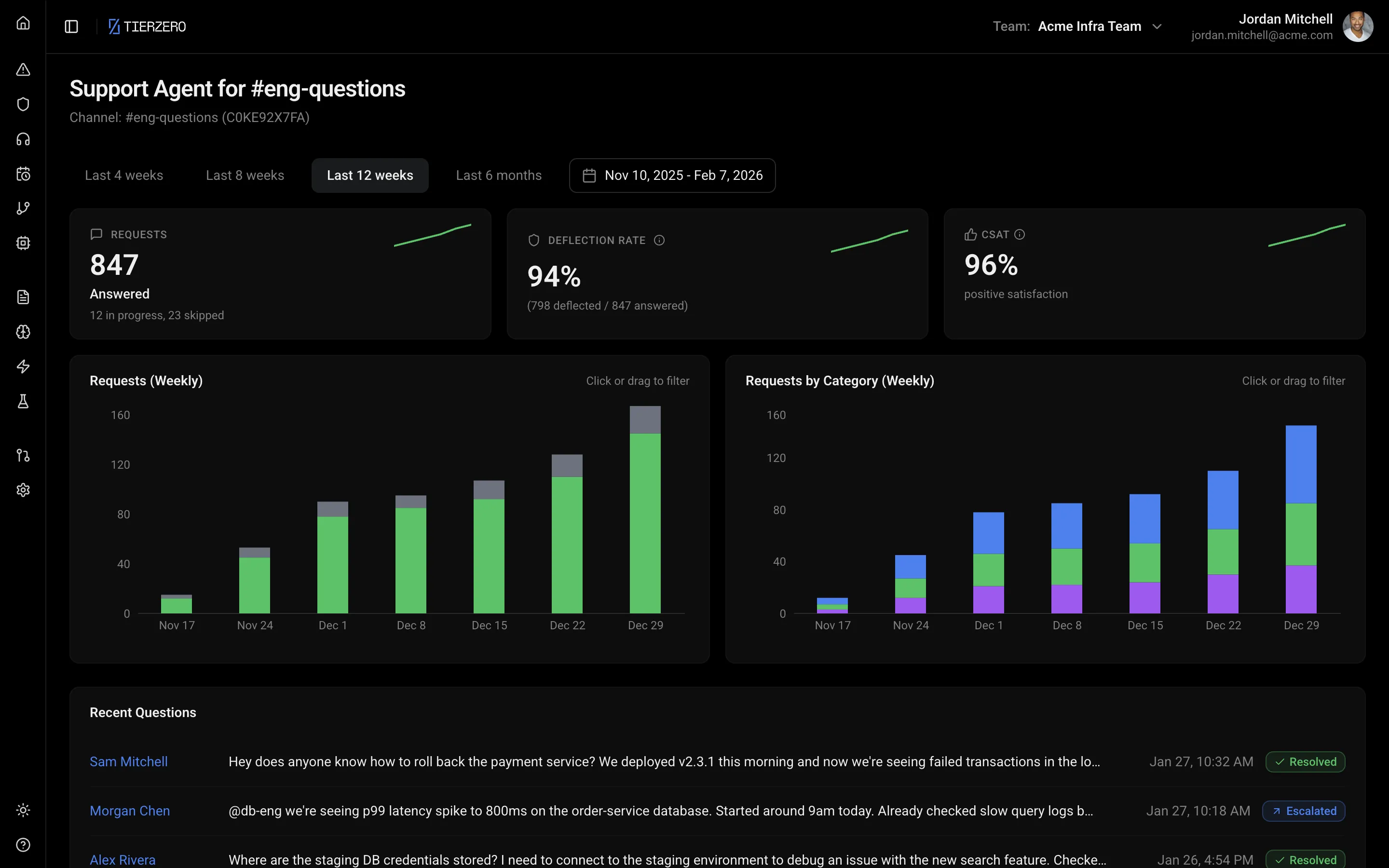
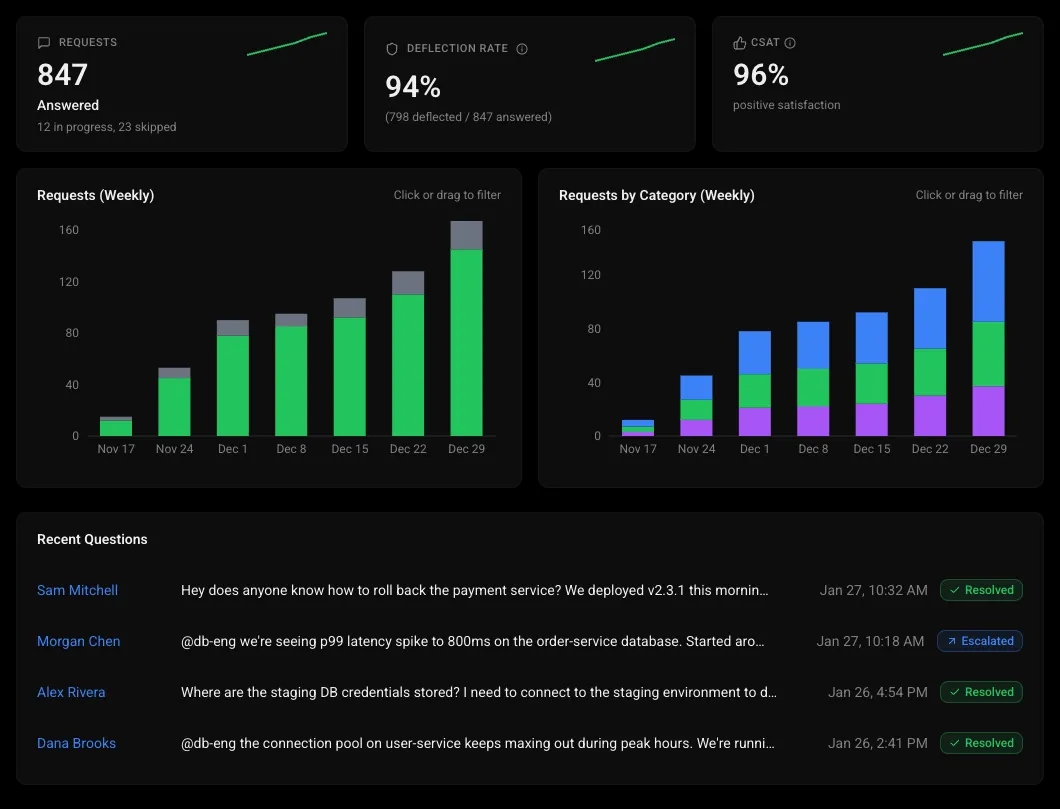
Track deflection rate, CSAT, and question categories out of the box. See which topics need better documentation, which answers get thumbs-down, and fine-tune the agent's behavior without writing code.
See what your team is really asking.
Every question is a signal. TierZero tracks what engineers ask, which topics have low-confidence answers, and where your documentation has gaps — so you can invest in the right places.
Question analytics
See trending topics, question volume, and auto-resolution rates across your team.
Knowledge gap detection
Automatically flags topics where answers are weak or missing, so you know exactly which runbooks to write.
Deflection tracking
Measure how many questions are resolved without escalating to a human — and track improvement over time.
From answers to actions.
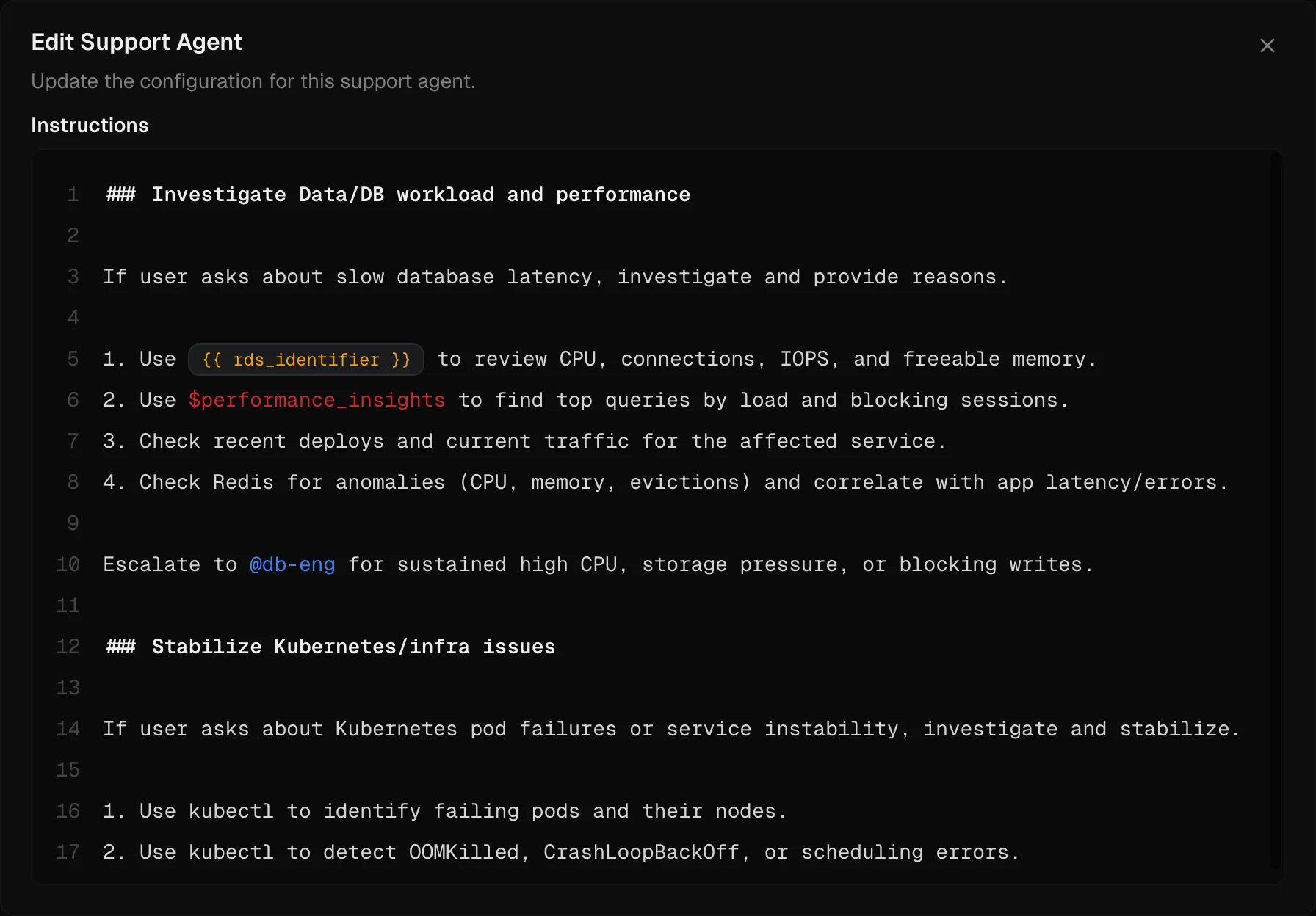
TierZero doesn't just tell engineers what to do — it can do it for them. Define SOPs for common operations and let engineers trigger them directly from Slack with guardrails built in.
Execute common ops
Restart pods, clear caches, scale deployments, rotate secrets — all from a Slack message.
Guardrails built in
SOPs run with scoped permissions, environment checks, and audit logging. No cowboy kubectl.
Self-service at scale
Junior engineers handle routine operations safely. Senior engineers stop being a human API.

Senior engineers got 3 hours a day back.
Questions Answered Without Escalation
Engineers get answers without pinging the on-call
Median Response Time
Versus hours waiting for a human reply