The 2026 AI SRE Buyer’s Guide
The 2026 AI SRE Buyer's Guide
A practical framework for evaluating AI agents for production operations. Built from real vendor evaluations and engineering team feedback. February 2026.
The AI SRE market is moving fast, and it's confusing. There are 40+ vendors across 7 archetypes, every observability vendor is bolting on AI features, and every incident management tool is adding an "AI agent." Some are genuinely useful. Many are not.
The vendor explosion is real
There are now 40+ vendors across 7 archetypes, from full-platform incumbents (Dynatrace, Datadog, New Relic) to pure-play AI SRE startups to cloud-native agents from AWS and Azure. Every observability vendor is bolting on AI features. Every incident management tool is adding an "AI agent." Some are genuinely useful. Many are not.
Feature checklists don't help
Most vendors claim to do investigation, root cause analysis, and automated remediation. In practice, "automated remediation" might mean a vendor recommends a kubectl command in a chat window. Or it might mean an agent that rolls back a bad deploy, restarts the affected pods, and opens a PR to fix the underlying issue, with approval gates at each step. The feature checkbox looks the same. The capability gap is enormous.
Most buyers learn the hard way
Teams that evaluate based on investigation demos alone end up with a tool that can explain what went wrong but can't do anything about it. Teams that skip the deployment model question discover during security review that their production data has to leave their environment. Teams that don't test with real incidents find out in week three that the agent only performs well on pre-staged scenarios.
This guide exists so you don't have to learn the hard way.
How to use this guide
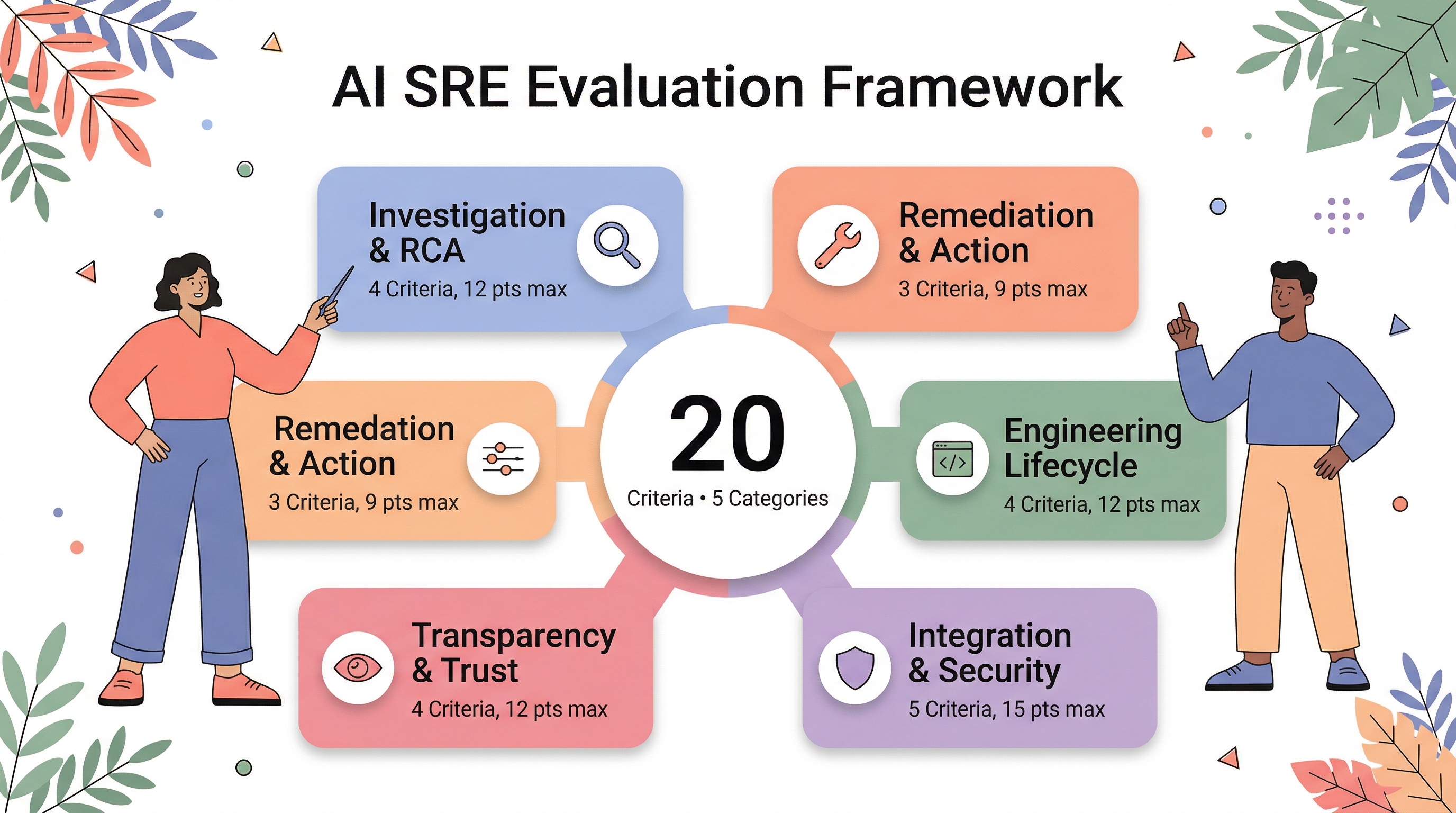
Five categories. Twenty criteria. A 1-3 scoring rubric. A 4-week POC structure. A build-vs-buy decision framework. Use it to score live demos, not feature lists. The categories ordered by what we've seen derail evaluations most often:
- Investigation & Root Cause Analysis — table stakes, but the differentiators are depth, speed, and evidence quality
- Remediation & Autonomous Action — investigation without action is a report
- Engineering Lifecycle Scope — most tools only activate when things break
- Integration, Deployment & Security — derails more evaluations than any other category
- Transparency, Trust & Maturity — the category most buyers skip